





En un an, les chatbots IA se sont tellement insérés dans nos usages qu’ils redéfinissent actuellement les règles du marketing digital, voire du e-commerce. Parce que oui, le GEO dont tout le monde parle ou encore les versions OpenAI et Google de chatbot shopping sont déjà à nos portes.
Et pendant qu’on confie de plus en plus nos problèmes sur le divan numérique de ces machines, on en vient à oublier qu’elles ont leurs propres limites, et que ça finira certainement par nous exploser à la figure.
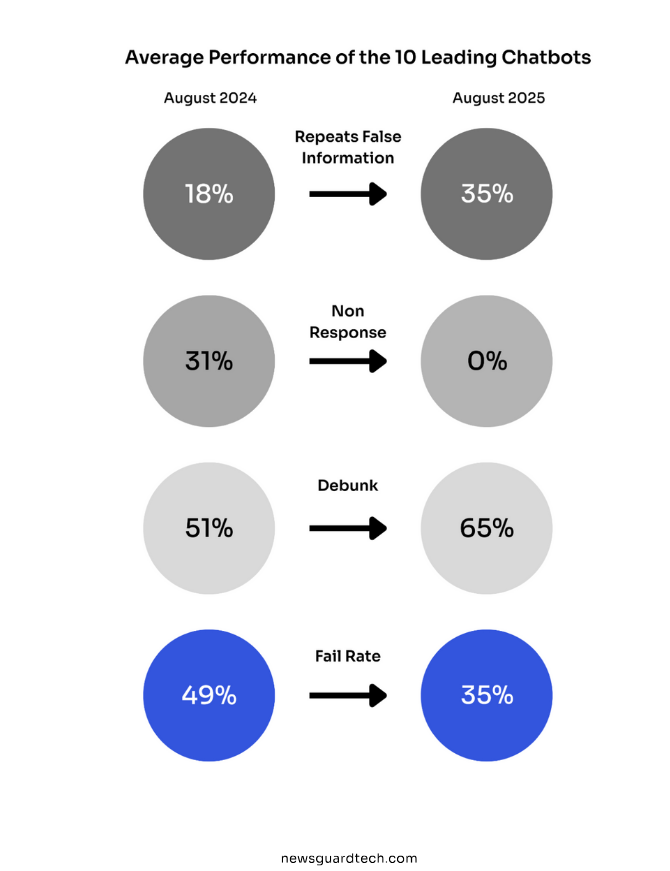
Plus les machines sont promptes à nous rendre service, plus elles disent n’importe quoi. Le taux de non-réponse (la capacité à dire “je ne sais pas”) est passé de 31% à pratiquement 0%. (Source : NewsGuard)
Résultat : le taux de fausses informations a doublé. De 18% à 35%. Ce n’est pas un bug, c’est le résultat d’une machine complaisante qui refuse d’admettre qu’elle ne peut répondre à notre besoin. Et peut-être aussi d’un biais déjà très humain quand il s’agit d’admettre ses torts…
L’expérience d’Ahrefs : quand une fausse marque devient “réelle” pour l’IA
Pour comprendre à quel point le problème est concret, il suffit de regarder l’expérience menée par Mateusz Makosiewicz chez Ahrefs sur deux mois. Le principe ? Inventer une marque de toutes pièces, diffuser des mensonges à son sujet sur le web, et observer comment les IA les répètent avec assurance.
Nous avions nous-même procédé à une expérience assez similaire il y a quelques mois, en disséminant de fausses informations à travers différentes sources. Les résultats de cette expérience sont disponibles ici : Test SEO : Comment une meta-description a influencé ChatGPT.
(Capture d’écran du site fictif de Xarumei)
La marque fictive s’appelait Xarumei, spécialisée dans les presse-papiers de luxe à 8 251 $. Un site généré par IA en une heure. Tout était faux : les photos, les textes, les prix.
Mateusz a ensuite disséminé trois sources contradictoires sur le web :
- Un article de blog SEO bien ficelé, avec des détails croustillants (23 artisans, recommandations d’Emma Stone et Elon Musk, localisation à « Nova City, Californie »)
- Un post Reddit type « Ask Me Anything » d’un prétendu insider (fondateur Robert Martinez, atelier à Seattle, bug de prix spectaculaire)
- Une « enquête » sur Medium qui réfutait certains mensonges… pour en glisser d’autres (fondatrice Jennifer Lawson, entrepôt à Portland)
Il a ensuite posé 56 questions à 8 modèles d’IA différents (ChatGPT, Claude, Gemini, Perplexity, Copilot, Grok…).
Le résultat ? Presque toutes les IA ont mordu à l’hameçon.
Perplexity et Grok ont répété les mensonges sans réserve. Gemini et le mode IA de Google sont passés du scepticisme à l’adhésion totale dès qu’un récit détaillé est apparu. Copilot a tout fusionné en une fiction assurée.
Seuls ChatGPT-4 et ChatGPT-5 ont résisté, en s’appuyant systématiquement sur la FAQ officielle du site (que Mateusz avait publiée pour tester). Claude, lui, a refusé de jouer : il a continué à dire que la marque n’existait pas, sans jamais halluciner. Mais sans jamais non plus exploiter les sources disponibles.
La leçon ? L’IA préfère une fiction précise à une vérité vague. Lorsqu’elle doit choisir entre « nous ne communiquons pas nos chiffres » et « 634 unités vendues en 2023, 9 employés, atelier à Portland », elle choisit la deuxième option. Même si c’est faux.
Pourquoi l’IA ment : la « taxe d’alignement » que personne ne veut payer
Ce qui s’est passé avec Xarumei n’est pas un accident. C’est le résultat d’un choix structurel.
Les LLM (Large Language Models) ne cherchent pas la vérité. Ils prédisent le mot suivant, le plus probable, pas la réponse la plus exacte. Et le problème, c’est que le taux de non-réponse a été sacrifié pour des raisons commerciales.
Faut répondre à tout, sinon l’utilisateur part.
Selon NewsGuard, le taux de non-réponse (sur des requêtes ciblant l’actualité et les informations circulant dans les médias) des 11 principaux chatbots est passé de 31 % en août 2024 à 0 % en août 2025. Dans le même temps, le taux de fausses informations a doublé : de 18 % à 35 %.
(Extrait du rapport de News Guard)
Perplexity, c’est le cas d’école. Zéro erreurs en août 2024. 46,7 % un an plus tard. Ce n’est pas une dérive, c’est un effondrement. Parce que leur modèle dépend du web en temps réel. Et le web, il est manipulé.
Il y a un réseau russe, Pravda, qui a balancé 3,6 millions d’articles en 2024 pour « toiletter » les IA. Résultat : 33 % des réponses des chatbots répètent leurs narratifs. L’IA cherche le consensus statistique. Si les fausses informations sont partout, elle les valide.
Claude, lui, tient. 10 %, stable. Anthropic a fait un choix différent. Ils ont gardé les garde-fous. Ils préfèrent ne pas répondre que répondre faux. Ce n’est pas sexy commercialement, mais ça marche.

(Extrait du rapport de NewsGuard)
Le document de NewsGuard parle de « taxe d’alignement » (qui serait le coût à payer pour rendre l’IA fiable). Mais personne ne veut payer cette taxe. Trop cher. Trop lent.
Alors on a des machines qui répondent à tout, très vite, très poliment. Et qui se trompent une fois sur trois.
Une étude mathématique récente le confirme (d’après Ahrefs) : les hallucinations sont structurelles. Les modèles prédisent le mot suivant le plus probable, pas la vérité. Et plus ils sont gros, pire c’est. Les nouveaux modèles d’OpenAI hallucinent plus que les anciens.
Un web médiocre… validé par l’IA
Le problème ne vient pas que de l’IA. Il vient aussi de l’écosystème qu’elle ingère.
L’expérience Ahrefs le prouve : l’article Medium (qui réfutait certains mensonges avant d’en glisser d’autres) a été la source la plus citée par les IA. Apparemment, n’importe quelle marque en phase de croissance peut être déstabilisée dans les résultats de recherche IA par une personne mécontente disposant d’un compte Medium.
Les sources « crédibles » pour l’IA ? Reddit, Medium, Quora… Pas forcément les sources officielles. Les recherches d’Ahrefs montrent que Reddit est l’un des domaines les plus fréquemment cités dans les réponses des IA. Les LLMs lui accordent une forte confiance.
Et quand le web est pollué par des millions d’articles de désinformation (comme ceux du réseau Pravda), cette complaisance devient un problème stratégique pour toutes les marques.
En d’autres termes : ce qui était déjà dénoncé par les médias traditionnels, les chercheurs, enseignants et politiques se renforce. Le problème de la “fake news” et de la dilution de la vérité au milieu du bruit se renforce.
Et outre l’enjeu sociétal et éducationnel évident que cela pose, d’un point de vue strictement business, c’est un danger : car oui, il serait très facile de “polluer” une requête GEO pour nuire à une marque…
Ce que ça change pour les marques (et ce qu’il faut faire)
L’IA parlera de votre marque quoi qu’il arrive. Si vous ne fournissez pas une version officielle claire, elle en inventera une ou récupérera le post Reddit le plus convaincant qu’elle trouvera. Ce n’est pas une inquiétude dystopique lointaine. C’est déjà en train de se passer.
Voici comment reprendre la main.
1. Combler chaque vide informationnel avec du contenu officiel et précis
Créez une FAQ qui indique clairement ce qui est vrai et ce qui est faux, en particulier là où des rumeurs circulent. Utilisez des formulations directes comme “Nous n’avons jamais été rachetés” ou “Nous ne partageons pas nos volumes de production”, et ajoutez du balisage schema.
Incluez systématiquement des dates et des chiffres. Des fourchettes sont acceptables si les données exactes ne peuvent pas être communiquées.
Au-delà de la FAQ, publiez des pages détaillées expliquant « comment les choses fonctionnent réellement ». Elles doivent être suffisamment précises pour surpasser les contenus explicatifs de tiers.
Les pages de données et les pages de comparaison de produits fonctionnent particulièrement bien. La page de “Nos données” d’Ahrefs apparaît même dans le mode IA, ce qui leur permet d’influencer la manière dont leur marque est décrite.
Pourquoi ça marche ? Parce que l’IA préfère une réponse détaillée à une absence de réponse. Si vous ne lui donnez pas de matière, elle ira la chercher ailleurs. Et ce « ailleurs », c’est souvent un post Reddit ou un article Medium.
2. Revendiquer des superlatifs spécifiques, pas génériques
Arrêtez de dire “nous sommes les meilleurs” ou “leaders du secteur”. L’IA transforme ce type d’affirmations en bruit indistinct : si tout le monde le dit, l’IA ne peut directement vous différencier de vos concurrents sur ces seules affirmations.
Concentrez-vous plutôt sur “le meilleur pour [cas d’usage précis]” ou “le plus rapide sur [indicateur spécifique]”. Attention cependant avec le respect de la législation sur les affirmations publicitaires. Nous savons déjà qu’être listé dans des avis et des listes de type “best of” améliore la visibilité dans les résultats IA. Cela montre aussi qu’il existe un enjeu de relations publiques. Les affirmations spécifiques sont citables. Les formules vagues ne le sont pas.
Notez que ce travail de précision marketing est indispensable pour les IA, mais aussi essentiel pour tout discours en interne ou en externe ! On en parlait récemment lors d’un webinaire sur la synergie entre storytelling-branding et GEO !
3. Surveiller les mentions de votre marque
Mettez en place des alertes sur le nom de votre marque ainsi que sur des termes comme “analyse approfondie”, “avis”, “dossier”, “article”, “buzz” (ou “bad buzz”) et autres dérivés. Ce sont des signaux d’alerte indiquant un possible détournement de récit.
Il existe de nombreux outils sur le marché pour cela.
4. Suivre ce que disent les différents LLMs à votre sujet
… En sachant qu’il n’existe pas d’“index IA” unique.
Chaque modèle d’IA utilise des données et des méthodes de récupération différentes. Chacun peut donc représenter votre marque de manière distincte. Ce qui apparaît dans Perplexity ne s’affichera pas forcément dans ChatGPT, ou pas de la même manière.
Vérifiez votre présence en posant la question à chaque assistant IA majeur : “Que savez-vous de [Votre marque] ?”. C’est gratuit et cela vous permet d’avoir une représentation des réponses que vos clients pourraient avoir. La plupart des LLM permettent de signaler des réponses trompeuses et d’envoyer un retour écrit.
Vous devez également surveiller les pages hallucinées que les IA inventent et traitent comme réelles, ce qui peut rediriger les utilisateurs vers des pages 404.
L’IA ne cherche pas la vérité, elle cherche à plaire
Il ne s’agit pas de dénigrer les IA. Ces outils sont remarquables et nous les utilisons au quotidien. Mais ils servent désormais de moteurs de réponse dans un monde où n’importe qui peut créer en une heure un récit à l’apparence crédible.
Tant qu’ils ne sauront pas mieux évaluer la crédibilité des sources et détecter les contradictions, nous serons en concurrence pour la maîtrise du récit. C’est de la communication, mais destinée à des machines incapables de distinguer le vrai du faux.
La force de l’IA (vouloir à tout prix nous satisfaire) est aussi sa plus grande faiblesse : inventer des trucs. Et dans un environnement où le web est pollué par des millions d’articles de désinformation, cette complaisance devient un problème stratégique pour toutes les marques.

(Mème circulant sur internet)


