





Le chunking fait couler beaucoup d’encre dans la communauté SEO. Est-ce une technique d’optimisation essentielle pour être repris par les IA, ou un simple buzzword sans impact réel ? Entre les détracteurs qui y voient du jargon recyclé et les partisans qui en font un pilier du GEO, ce concept divise. Pourtant, derrière le débat se cache une réalité technique précise : la manière dont les modèles de langage (LLM) analysent et découpent les contenus. Décryptage d’une pratique qui pourrait bien transformer votre façon d’écrire pour le web.
Qu’est-ce que le chunking, concrètement ?
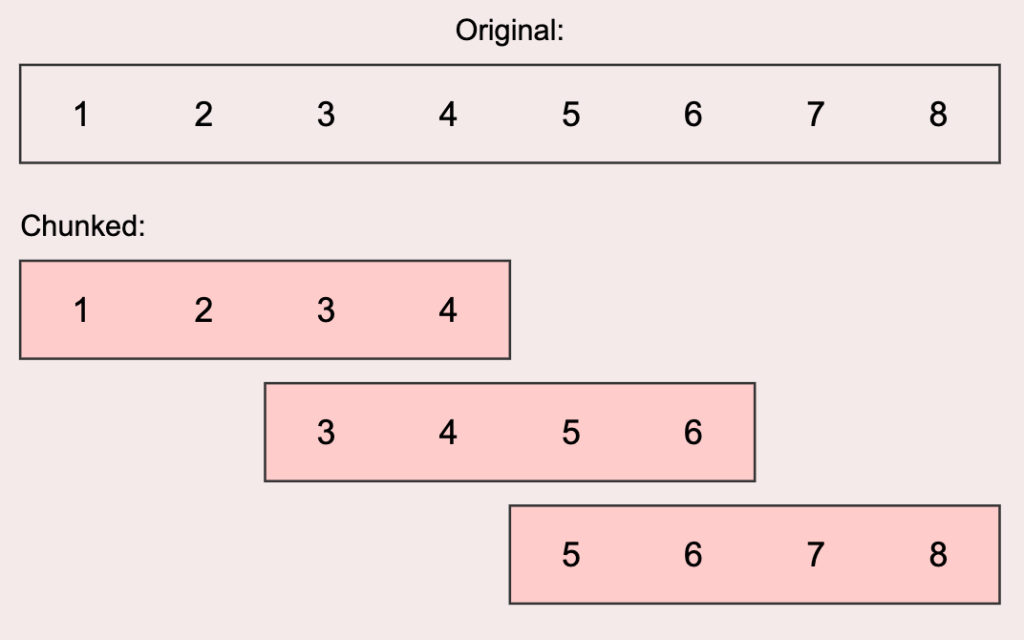
Le chunking désigne le fait de structurer un contenu en passages courts (150 à 300 mots) et auto-suffisants. Autrement dit : chaque section doit pouvoir être comprise isolément, sans avoir besoin de lire ce qui précède ou ce qui suit.
Cette notion d’auto-suffisance est centrale. Si vous extrayez un passage de votre article et que le message reste clair, vous avez réussi votre chunk.
Exemple d’un bon chunk :
Le référencement local désigne l’ensemble des techniques permettant à une entreprise d’apparaître dans les résultats de recherche géolocalisés. Cette stratégie est particulièrement cruciale pour les commerces de proximité, les restaurants ou les services à domicile qui cherchent à capter une clientèle dans leur zone de chalandise.
Le référencement local repose sur trois piliers complémentaires. D’abord, l’optimisation de la fiche Google Business Profile, qui centralise les informations essentielles : adresse, horaires, photos et avis clients. Ensuite, la cohérence des NAP (Name, Address, Phone) sur l’ensemble des annuaires en ligne, qui renforce la crédibilité aux yeux de Google. Enfin, l’obtention d’avis clients authentiques, qui jouent un rôle déterminant dans le classement local et la décision d’achat.
Ce passage de ~220 mots contient une définition claire, un développement logique et une conclusion naturelle. Il peut être compris sans contexte externe.
Pourquoi le chunking intéresse-t-il les IA ?
Pour comprendre l’intérêt du chunking, il faut remonter au fonctionnement des Transformers, l’architecture qui a permis le développement des LLM comme GPT ou BERT (le « T » dans ces acronymes).
Le mécanisme de la fenêtre glissante
Lors de la phase d’entraînement, un Transformer analyse chaque contenu en déplaçant une fenêtre de contexte qui contient quelques centaines de mots maximum. Il analyse finement chaque terme et sa relation avec son contexte immédiat, puis déplace sa fenêtre pour traiter le morceau suivant.
Entre deux fenêtres, un recouvrement de 10 à 20 % est appliqué selon les modèles, pour éviter de perdre le fil du sens.
(Illustration d’un concept de fenêtre glissante)
Cette logique de fenêtre glissante se retrouve aussi dans les outils RAG (Retrieval Augmented Generation) comme Perplexity, SearchGPT ou Bing Copilot. Lorsque ces systèmes vont chercher des sources sur le web, ils calculent des vecteurs d’embeddings en appliquant le même principe.
Définition : Vecteur d’embedding
Un vecteur d’embedding est une liste de nombres utilisée pour représenter un mot, une phrase ou tout autre élément sous une forme que les algorithmes d’intelligence artificielle peuvent traiter.
Son principe clé est de positionner les éléments ayant un sens similaire (par exemple, « chien » et « chiot ») très proche les uns des autres dans l’espace numérique.
Pourquoi ça marche ?
Imaginons qu’un utilisateur demande : “Comment apparaître dans Google Maps pour mon restaurant ?”
Le système RAG :
- Trouve le chunk pertinent via la similarité sémantique
- Le fournit au LLM qui peut générer une réponse complète
- N’a pas besoin de reconstituer un puzzle d’informations fragmentées
C’est la différence entre donner à quelqu’un un chapitre complet d’un livre, ou des pages déchirées au hasard.
Les limites techniques : la complexité quadratique
Les Transformers utilisent un mécanisme d’attention pour comprendre le texte. Pour chaque mot, le modèle doit examiner tous les autres mots afin de saisir le contexte. Le problème ? Le nombre d’analyses nécessaires augmente selon le carré de la longueur de la fenêtre.
| Longueur du texte | Nombre d’analyses de contexte |
| 100 mots | 10 000 analyses |
| 1 000 mots | 1 000 000 analyses |
| 10 000 mots | 100 000 000 analyses |
Agrandir la fenêtre produit une explosion combinatoire du temps de calcul et des ressources nécessaires. C’est pourquoi les modèles privilégient des passages plus courts et mieux structurés.
Quelle est la longueur idéale d’un chunk ?
On raisonne en tokens, pas en mots. Les textes sont convertis en tokens (jetons) qui correspondent souvent à des mots, mais peuvent aussi être des espaces, des signes de ponctuation ou des morceaux de mots.
Règle de conversion :
- Un texte de 200 mots = environ 250 tokens (soit 25 % de tokens en plus)
Longueur recommandée :
- 200 à 400 tokens (soit environ 150 à 300 mots)
Cette taille est suffisamment courte pour être traitée efficacement, et suffisamment longue pour contenir une information complète.

(Source : Exemple de découpage d’un texte en token – site IBM)
Les 4 caractéristiques d’un bon chunk
| Critère | Description |
| Autonomie complète | Aucune référence à « comme mentionné précédemment » ou « nous verrons plus tard ». Le chunk doit avoir du sens lu isolément. |
| Unité thématique | Un seul sujet par chunk, avec une progression logique (définition → mécanisme → importance). |
| Taille optimale | Entre 150 et 300 mots : assez court pour être traité efficacement, assez long pour être complet. |
| Structure claire | Introduction (définition) + Développement (explication) + Synthèse (conclusion naturelle). |
Ce qu’il ne faut surtout pas faire
❌ Mélange thématique incohérent
« Le référencement local est essentiel pour les commerces de proximité. Il permet d’apparaître dans Google Maps. Les entreprises doivent également travailler leur présence sur les réseaux sociaux. Par exemple, Instagram est idéal pour les restaurants. Le marketing d’influence génère beaucoup d’engagement. Les campagnes Google Ads peuvent aussi booster la visibilité rapidement. »
Problèmes :
- Saut thématique constant (référencement local → réseaux sociaux → influence → publicité)
- Pas d’unité conceptuelle
- Le LLM aura du mal à déterminer le sujet principal

Demandez votre pré-audit GEO gratuit !
Votre stratégie SEO est-elle prête pour l’ère des navigateurs intelligents ? Notre laboratoire analyse ces évolutions et vous accompagne dans cette transition vers le GEO. Échangeons sur les enjeux de votre secteur et recevez votre premier pré-audit GEO.
❌ Références ambiguës
« Cette stratégie améliore la visibilité dans les résultats géolocalisés. Elle repose sur plusieurs éléments clés. Le premier concerne ces informations essentielles qui doivent être cohérentes partout. Le second élément utilise ce qui a été créé précédemment pour renforcer la crédibilité. Cela permet d’obtenir de meilleurs résultats. »
Problèmes :
- Pronoms et références vagues (« cette stratégie », « ces informations », « ce qui a été créé »)
- Aucune information concrète
- Trop générique : pourrait décrire n’importe quelle stratégie marketing
❌ Information fragmentée
« Google Business Profile est important. Les avis clients influencent le classement. Les NAP doivent être cohérents. Les horaires d’ouverture sont affichés. Les photos attirent les clients. Les mots-clés locaux sont utiles. La géolocalisation fonctionne avec GPS. Les annuaires en ligne existent. »
Problèmes :
- Phrases déconnectées : liste de faits sans liens logiques
- Pas de flow narratif
- Le LLM devra reconstituer les connexions, risquant des erreurs
Comment structurer un contenu pour optimiser le chunking ?
La bonne nouvelle : vous pouvez produire des chunks optimisés sans le savoir, un peu comme Monsieur Jourdain faisait de la prose. Mais cela n’arrive que si vous structurez votre texte à partir d’un plan détaillé.
Méthode 1 : Le plan détaillé
Voici un exemple pour un contenu sur le référencement local :
I. Le référencement local (chunk 1)
- A. Définition et enjeux
- B. Les acteurs : Google Business Profile et écosystème local
II. Optimisation de la fiche Google Business Profile (chunk 2)
- A. Informations essentielles à renseigner
- B. Gestion des avis clients
- C. Ajout de photos et posts réguliers
III. Cohérence des citations locales (chunk 3)
- A. Importance des NAP (Name, Address, Phone)
- B. Annuaires et plateformes à privilégier
- C. Suivi et correction des incohérences
Méthode 2 : Pyramide inversée + plan
Combiner les deux approches donne les meilleurs résultats :
Article complet
Introduction [Chunk 1 – Pyramide inversée]
- Résumé complet en 250 tokens
- Contient toutes les infos essentielles
- Autonome et facilement repérable
Section 1 [Chunk 2]
Titre explicite : Optimiser sa fiche Google Business Profile
- Intro de la section (rappel minimal du contexte)
- Développement complet
- Conclusion de section
Section 2 [Chunk 3]
Titre explicite : Assurer la cohérence des NAP sur les annuaires
- Intro de la section
- Développement complet
- Conclusion de section
Le débat qui divise la communauté SEO
🚫 Les détracteurs : « Le chunking est un mirage »
Nikki Pilkington estime que le terme est surtout du jargon marketing recyclé :
“Ce que les experts GEO appellent chunking, c’est en réalité ce que les SEO recommandent depuis 2009 : des titres clairs, une idée par section et des paragraphes concentrés. On ne peut pas optimiser pour le chunking, puisque ce n’est pas un levier SEO, mais un terme technique venu de l’IA.”
Despina Gavoyannis souligne l’impossible maîtrise de ce processus :
“Vous ne pouvez pas contrôler comment Google, ChatGPT ou Perplexity découpent vos contenus. Chaque modèle applique ses propres stratégies, basées sur des considérations techniques.”
Dan Petrovic, qui a décortiqué le code source de Chrome, rappelle que le chunking est avant tout un choix d’ingénierie intégré aux systèmes eux-mêmes :
“L’algorithme DocumentChunker de Chrome découpe chaque page web en passages sémantiques d’environ 200 mots. Ce découpage est entièrement automatique, basé sur la structure HTML et conçu pour être optimisé par le navigateur, pas par le rédacteur.”
✅ Les partisans : « Le chunking est incontournable »
Philippe Yonnet défend une approche structurée :
“Le chunking, c’est produire des passages de 150 à 300 mots 100 % compréhensibles même pris isolément. Cette méthode est adaptée aux limites des transformers, qui analysent les textes par fenêtres successives de quelques centaines de tokens. Des chunks cohérents maximisent les chances d’être repris par les systèmes RAG comme Perplexity ou Bing Copilot.”
Aishwarya Srinivasan insiste sur les bénéfices tangibles dans une pipeline RAG :
“Mauvais découpage = résultats non pertinents. Découpage intelligent = meilleur ancrage, plus grande précision, réponse plus rapide. Le moyen dont vous découpez vos documents impacte directement la qualité des réponses générées.”
Elle met en avant des techniques avancées :
- Overlap Chunking : préserver le contexte entre deux passages
- Semantic-Based Chunking : découper selon les changements de sens, pas des longueurs fixes
- Modality-Aware Chunking : adapter le découpage aux documents mélangeant texte, tableaux ou images
Quels résultats attendre ?
Les retours d’expérience et études récentes esquissent des résultats intéressants :
Données chiffrées
- Étude de Princeton (2024) : une structuration adaptée permet d’augmenter la visibilité de 27 % à 41 % dans les systèmes RAG et les SERP enrichis.
- Marie Haynes, consultante SEO canadienne : constate une amélioration de 15 % sur la visibilité avec cette approche.
Impact SEO classique
En structurant vos textes « comme pour le chunking » (une idée par section, paragraphes courts, titres clairs), vous observez :
- Une meilleure reprise par les moteurs à base de LLM (Google, Bing, Perplexity)
- Un impact positif sur le SEO classique : taux de lecture plus élevés, sections mieux valorisées
- Une meilleure indexation des réponses ciblées
Compréhension humaine
Un texte chunké est plus scannable, facilite l’accès rapide à l’information et rend le contenu plus accessible, aussi bien pour le grand public que pour les professionnels.
Faut-il optimiser tout son contenu ?
Non. Si des passages sont des chunks corrects et d’autres non, cela n’a pas de conséquences graves.
En pratique, seuls les chunks optimisés ont des chances augmentées d’être visibles dans les réponses. Les autres risquent de ne pas être choisis, mais le pire n’est pas sûr, notamment en l’absence de contenus jugés plus pertinents.
Cela autorise des stratégies ciblées, notamment pour les contenus existants : seules les parties contenant des informations importantes ou que vous souhaitez rendre visibles seront optimisées.
À retenir : checklist du chunking
Notre point de vue chez Semjuice
Le chunking n’est ni une recette miracle, ni un buzzword inutile. C’est une réponse technique à une contrainte réelle : la manière dont les modèles de langage analysent et découpent les contenus.
Chez Semjuice, nous intégrons ces bonnes pratiques dans nos accompagnements SEO et nos productions de contenus. Pourquoi ? Parce que :
- C’est bon pour le GEO : vos contenus ont plus de chances d’être repris par les IA
- C’est bon pour le SEO : les algorithmes de Google et Bing embarquent déjà des couches utilisant des LLM
- C’est bon pour vos lecteurs : un contenu structuré est plus lisible et plus actionnable
Le chunking n’est pas une fin en soi, mais un accélérateur de visibilité et de compréhension. Et dans un environnement où les IA jouent un rôle croissant dans la découverte de contenus, c’est un levier qu’il serait dommage d’ignorer.
Vous souhaitez optimiser vos contenus pour le SEO et le GEO ? Chez Semjuice, nous vous accompagnons dans la production de contenus structurés, pensés pour être compris autant par les humains que par les IA. Parlons-en →


